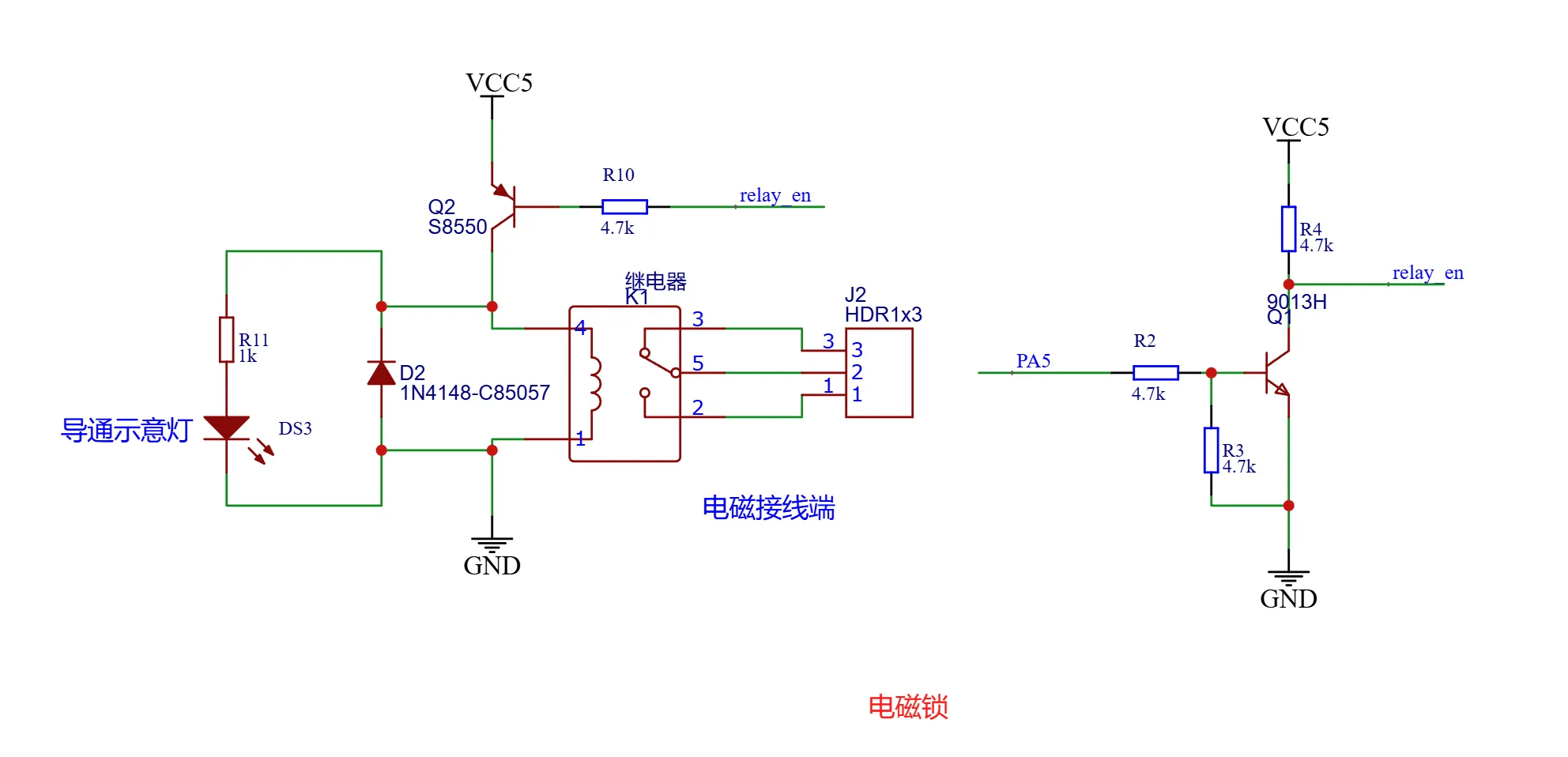
MOSFET关闭状态
当箭头所指位置输入高电平时,可以分析9013的集电极(C)电压。假设输入高电平为3.3V,具体情况如下:
-
基极电流:箭头输入高电平时,9013的基极通过R2(4.7kΩ)和基极到发射极电压(通常为0.7V)建立基极电流。此时,基极电流约为 ((3.3V - 0.7V) / 4.7kΩ ≈ 0.55mA)。
-
三极管导通:由于9013的基极电流足够大,三极管进入饱和导通状态。
-
集电极电压:在饱和状态下,三极管的集电极电压 ( V_{CE(sat)} ) 通常在 0.2V 到 0.3V 之间。因此,在输入高电平时,9013的集电极电压接近于0V(即接地)。
因此,当箭头所指位置输入高电平时,9013的集电极电压应约为 0.2V到0.3V之间,接近于0V。
开关电路
在开关电路设计中,MOSFET通常被用作电子开关,能够控制电流的通断。MOSFET开关的设计需要考虑MOSFET的类型、极性(N沟道或P沟道)、驱动电压、电流负载等参数。以下是MOSFET作为开关使用时的基本设计思路和接线方法。
1. 确定MOSFET类型
MOSFET有N沟道和P沟道之分。在开关电路中,N沟道MOSFET通常用于低端开关(接地端开关),而P沟道MOSFET通常用于高端开关(电源端开关)。
- N沟道MOSFET:漏极(Drain,D)通常接负载的负端,源极(Source,S)接地。栅极(Gate,G)通过一个合适的电压控制MOSFET的导通和关断。
- P沟道MOSFET:源极(S)通常接电源,漏极(D)接负载的正端。控制栅极和源极之间的电压差,使其导通或关断。
师从:https://www.bilibili.com/read/cv4088568/
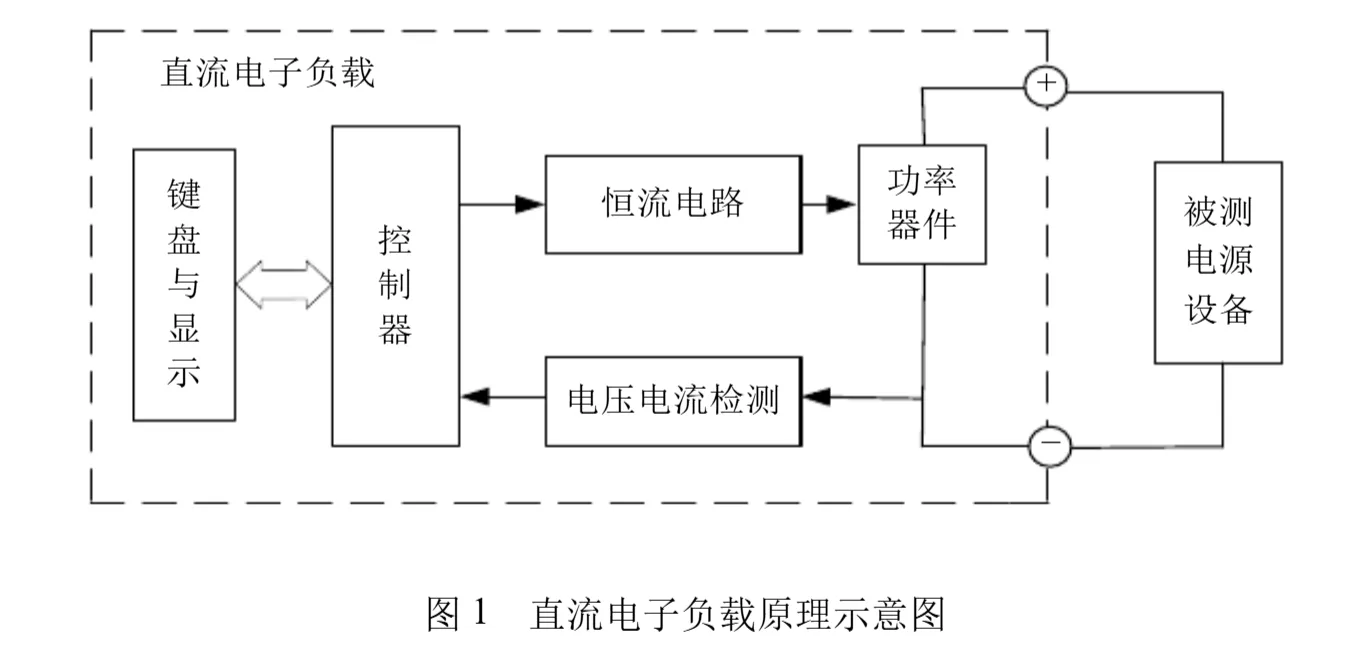
题目是这样的: 设计和制作一台恒流(CC)工作模式的简易直流电子负载。其原理示意图如图1所示。
图1简易直流电子负载原理示意图
二、要求 1.基本要求 (1)恒流(CC)工作模式的电流设置范围为100mA~1000mA,设置分辨率为100mA,设置精度为 ±1%。还要求CC工作模式具有开路设置,相当于设置的电流值为零。
(2)能实时测量并数字显示电子负载两端的电压,测量精度为±(0.1%+0.1%FS)。
(3)能实时测量并数字显示流过电子负载的电流,电流测量精度为±(0.2%+0.2%FS)。
2.发挥部分 (1)自制一个稳压电源(允许采用集成稳压芯片),以供测试直流电子负载性能时使用。要求稳压电源的输出电压为5V±0.1V,额定输出电流大于1A,纹波与噪声电压(峰峰值)不大于20mV。
(2)编程使制作的简易直流电子负载具有负载调整率自动测试功能,要求负载调整率的测试范围为1.0%~19.9%,测量精度为±1%。采用简易直流电子负载测试自制稳压电源的负载调整率,其测试示意图如图2所示。为了便于测试,图中加入了电阻RW,更换不同阻值的RW,可以改变被测电源的负载调整率。
图2稳压电源及负载调整率测试示意图
(3)进一步提高电压测量和电流测量的精度,并将直流电子负载的负载调整率测试范围扩展为0.1%~19.9%,测量精度为±1%。
(4)其他。
三、说明 1、在恒流(CC)模式下,不管电子负载两端电压是否变化,流过电子负载的电流为一个设定的恒定值,该模式适合用于测试直流稳压电源的调整率,电池放电特性等场合。
2、直流稳压电源负载调整率是指电源输出电流从零至额定值变化时引起的输出电压变化率。本题负载调整率的测量过程要求自动完成,即在输入有关参数后,能直接给出电源的负载调整率。
一、恒流电子负载介绍
恒流电子负载是一种电子设备,用于模拟恒定电流消耗的负载,它在测试和评价电源(如电池、稳压电源、开关电源等)性能时非常有用。恒流电子负载可以根据设定的电流值,稳定地吸收指定电流,而不受电源输出电压波动的影响。这类设备广泛应用于电子测试领域,用于测试电源在不同负载条件下的响应和稳定性。
https://arxiv.org/abs/2312.13771
https://github.com/mnotgod96/AppAgent
《AppAgent:作为智能手机用户的多模态代理》摘要
摘要与引言:
本文介绍了AppAgent,一种新颖的框架,利用多模态大型语言模型(LLMs)以类似人类用户的方式操作智能手机应用程序。与传统的智能助手(如Siri)不同,后者需要后端系统访问和功能调用,AppAgent 直接通过简化的人类操作(如点击和滑动)与应用界面互动。这种方法增强了安全性,扩大了适用范围,并确保了对用户界面(UI)变化的适应性,无需广泛的再训练或后端集成。
https://arxiv.org/abs/2406.01014
论文总结
论文标题: Mobile-Agent-v2: A Multi-Agent Framework for Enhanced Mobile Device Operation Assistance
研究方向: 多模态大语言模型(MLLMs)在移动设备操作任务中的应用,通过多智能体架构提升导航效率和任务完成率。
1. 研究背景与动机
- 多模态AI应用场景的兴起: 移动设备操作任务作为多模态AI的重要应用场景,需求日益增长。
- 单智能体架构的局限性: 现有的基于MLLM的单智能体(如Mobile-Agent)在处理长序列的任务进度导航和焦点内容导航时表现不佳,主要受限于冗长的token序列和交错的文本-图像数据格式,导致任务完成率低(如Mobile-Agent成功率仅为20%)。
mobile-agent : autonomous multi-modal mobile device agent with visual perception
这是v1版本
https://arxiv.org/abs/2401.16158
摘要
基于多模态大语言模型(Multimodal Large Language Models, MLLM)的移动设备代理正在成为一种流行的应用。在本文中,我们介绍了一种自主多模态移动设备代理——Mobile-Agent。Mobile-Agent 首先利用视觉感知工具精确识别并定位应用前端界面中的视觉和文本元素。基于视觉上下文的感知,Mobile-Agent 然后自主规划并分解复杂的操作任务,逐步引导完成移动应用中的操作。不同于依赖应用 XML 文件或移动系统元数据的早期解决方案,Mobile-Agent 采用以视觉为核心的方法,能够在不同的移动操作环境中更具适应性,从而无需特定系统的定制化支持。为了评估 Mobile-Agent 的性能,我们引入了 Mobile-Eval,一个用于评估移动设备操作的基准。基于 Mobile-Eval,我们对 Mobile-Agent 进行了全面的评估。实验结果表明,Mobile-Agent 在操作准确性和完成率方面表现显著,即使面对多应用操作等复杂指令,Mobile-Agent 依然能够完成要求。代码和模型已开源于 https://github.com/X-PLUG/MobileAgent。
增加用户:
bash展开代码sudo useradd -m -s /bin/bash zhangsan
将用户 zhangsan 添加到 sudo 组:
bash展开代码sudo usermod -aG sudo zhangsan
让 sudo 组的用户免密码执行 sudo。
在 /etc/sudoers 中找到以下行(通常被注释):
plaintext展开代码# %sudo ALL=(ALL:ALL) NOPASSWD: ALL
去掉注释(删除行首的 #):
plaintext展开代码%sudo ALL=(ALL:ALL) NOPASSWD: ALL
摘要
本文介绍了一种称为“应用代理(app agents)”的全新移动电话控制架构,用于高效地在各种Android应用之间进行交互和控制。提出的轻量级多模态应用控制(LiMAC)系统,以文本目标和一系列先前的移动观察数据(如截图和对应的UI树)作为输入,生成精确的操作。为了解决智能手机本身的计算限制,LiMAC内引入了一个小型的动作转换器(Action Transformer,简称AcT),并集成了一个微调的视觉语言模型(VLM),以实现实时的决策与任务执行。在两个开源移动控制数据集上的评估结果表明,我们的小型架构在性能上明显优于微调后的开源VLM(如Florence2和Qwen2-VL),并大幅超越了基于封闭源基础模型(如GPT-4o)进行的提示工程基线。具体而言,LiMAC将整体操作精度提高了19%,相比提示工程基线高出42%。