虚拟机安装 openssh-server
要从主机电脑通过SSH连接到VMware Workstation中的虚拟机,您需要确保以下几点:
- 虚拟机有SSH服务:您的虚拟机需要安装并运行SSH服务。例如,在基于Debian/Ubuntu的系统上,您可以通过以下命令安装SSH服务:
bash展开代码
sudo apt update sudo apt install openssh-server sudo systemctl enable ssh sudo systemctl start ssh sudo vim /etc/ssh/sshd_config # 修改配置,如果想修改的话,修改后重启ssh
在Ubuntu桌面版中,您可以通过以下步骤设置自动登录,从而避免每次输入密码进入系统:
- 打开“设置”。
- 在左侧面板中,找到并点击“用户”。
- 选择要自动登录的用户。
- 点击“解锁”并输入您的密码以进行更改(如果系统提示,需要输入当前用户的密码)。
- 找到“自动登录”选项,并将其打开。然后reboot就可以了。
进行上述操作后,下次启动Ubuntu时便会自动登录到所选用户账户。
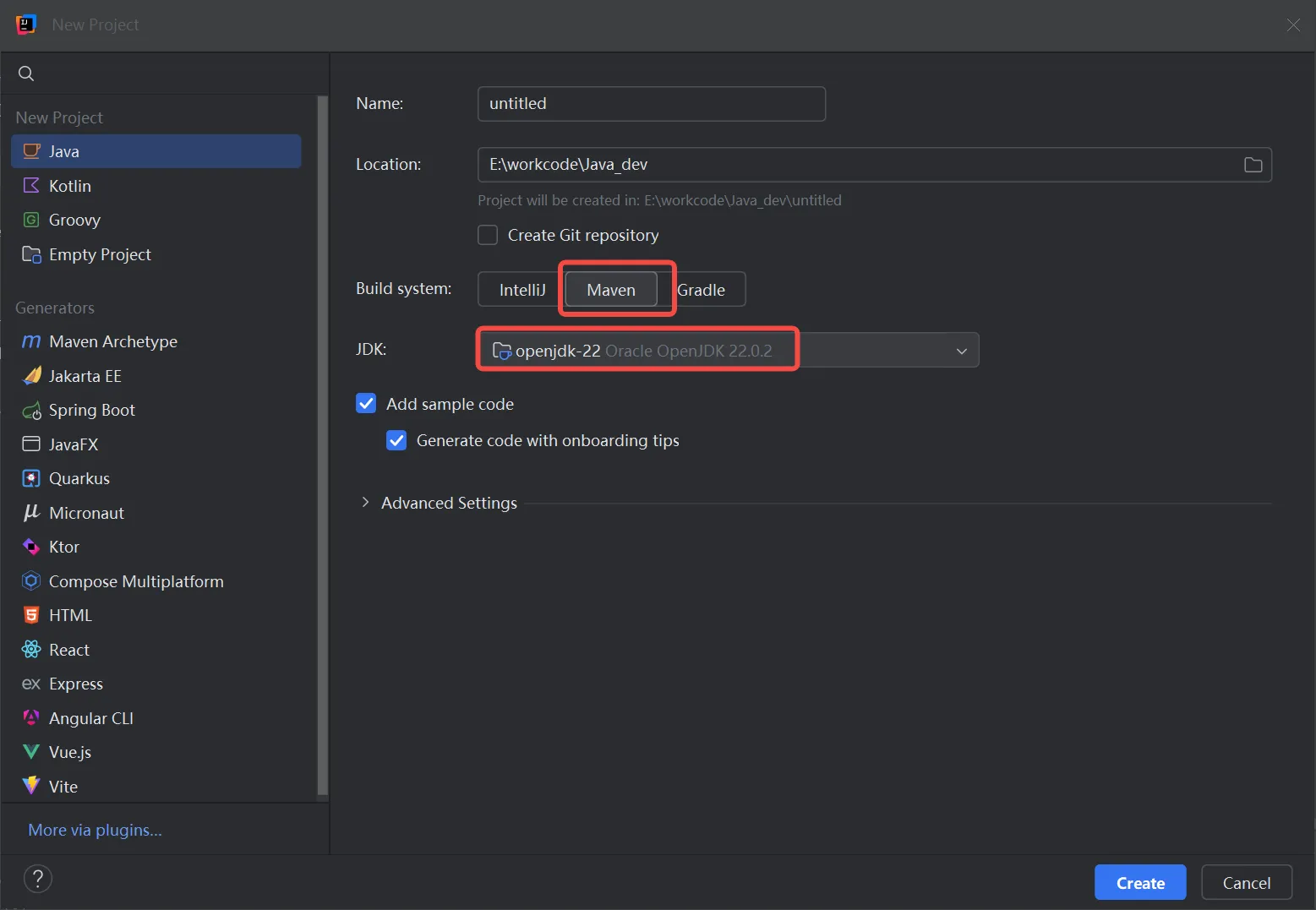
1. 新建工程
如果你的团队较为熟悉 Maven,项目需要稳定且有严格的结构标准 ,Maven 可能是一个不错的选择。
如果你追求构建速度更快、构建脚本更简洁和灵活性 ,那么 Gradle 可能会更适合你。
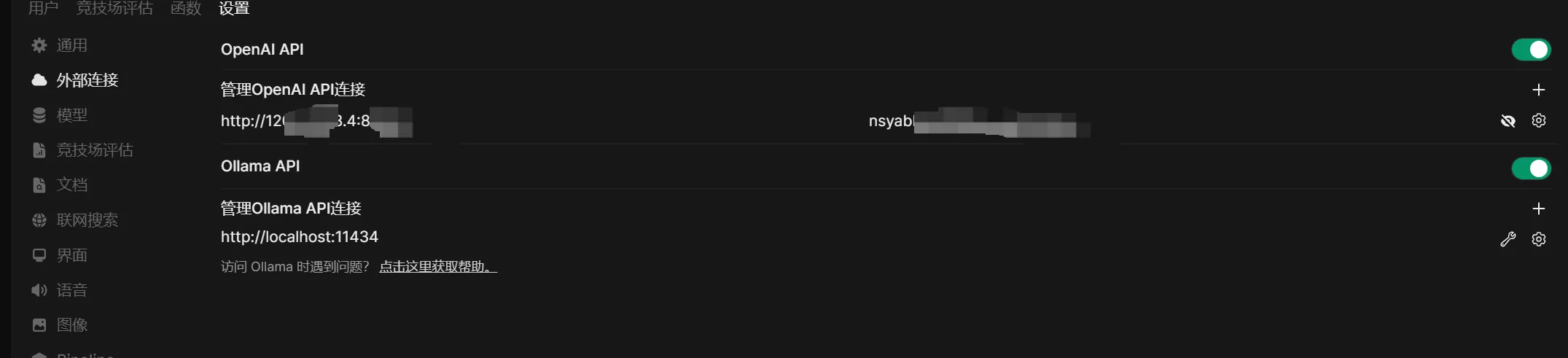
带ollama的镜像:
展开代码docker run -d -p 8888:8080 \ -v /root/ollama:/root/.ollama \ -v /root/openwebui-test:/app/backend/data \ --restart always -e HF_HUB_OFFLINE=1 \ ghcr.io/open-webui/open-webui:ollama
不要Ollama:
展开代码docker run -d -p 8888:8080 -v /root/openwebui-test:/app/backend/data --restart always ghcr.io/open-webui/open-webui:main docker run -d -p 8888:8080 -v /root/openwebui-test:/app/backend/data --restart always dockerproxy.com/kevinchina/deeplearning:openwebui
ollama
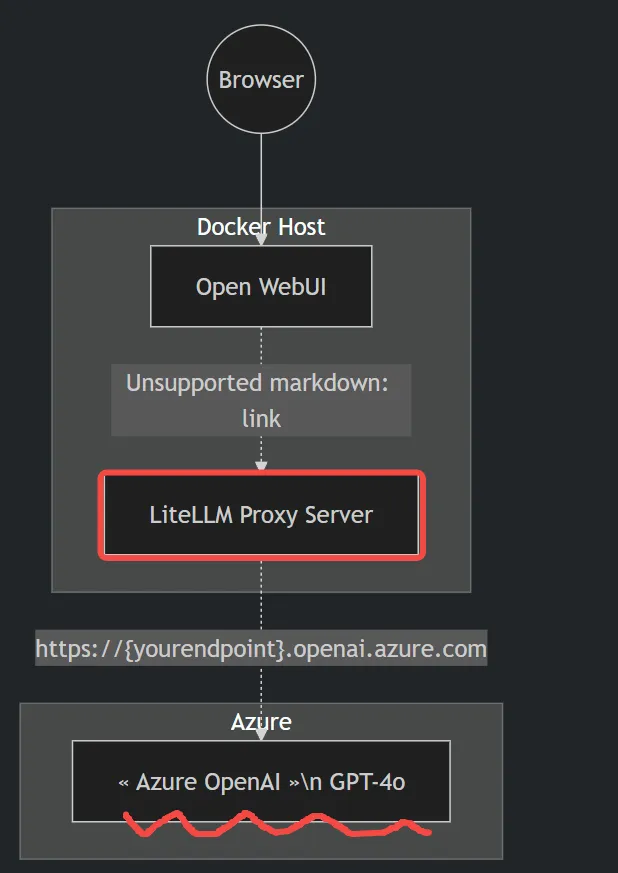
https://uright.ca/blogs/2024-07-29-unlocking-the-power-of-azure-openai-on-open-webui/
使用 litellm 简化 Azure GPT-4 调用
litellm 是一个统一接口库,它可以将 Azure 和 OpenAI 的接口规范统一,方便开发者使用。下面是如何通过 litellm 进行简单的 Azure GPT-4 调用。