image_max_pixels
image_max_pixels, 这里的 area 就是宽*高
python展开代码# 在src/llamafactory/data/mm_plugin.py中定义
# 控制图像处理时的最大像素数量
# 如果图像超过这个像素数,会被调整大小
def get_image_processor_preprocess_params(image_processor):
params = {}
if hasattr(image_processor, "crop_size"): # for CLIP
params["crop_size"] = {
"height": image_processor.crop_size["height"],
"width": image_processor.crop_size["width"]
}
params["size"] = max(params["crop_size"]["height"], params["crop_size"]["width"])
elif hasattr(image_processor, "size"):
if isinstance(image_processor.size, dict): # for Qwen
params["size"] = image_processor.size["max_edge"]
elif isinstance(image_processor.size, list): # for InternVL
params["size"] = image_processor.size
else:
params["size"] = image_processor.size
# image_max_pixels用于确保图像不会太大,超出内存
if params.get("size", None) is not None and hasattr(image_processor, "image_max_pixels"):
area = image_processor.image_max_pixels # 来自training_args.image_max_pixels
size = int(math.sqrt(area))
params["size"] = size
return params
LLaMA-Factory 源码信息
展开代码register_model_group( models={ "InternVL2.5-1B-MPO": { DownloadSource.DEFAULT: "kingsley01/InternVL2_5-1B-MPO-hf", DownloadSource.MODELSCOPE: "llamafactory/InternVL2_5-1B-MPO-hf", }, "InternVL2.5-2B-MPO": { DownloadSource.DEFAULT: "kingsley01/InternVL2_5-2B-MPO-hf", DownloadSource.MODELSCOPE: "llamafactory/InternVL2_5-2B-MPO-hf", }, "InternVL2.5-4B-MPO": { DownloadSource.DEFAULT: "kingsley01/InternVL2_5-4B-MPO-hf", DownloadSource.MODELSCOPE: "llamafactory/InternVL2_5-4B-MPO-hf", }, "InternVL2.5-8B-MPO": { DownloadSource.DEFAULT: "kingsley01/InternVL2_5-8B-MPO-hf", DownloadSource.MODELSCOPE: "llamafactory/InternVL2_5-8B-MPO-hf", }, "InternVL3-1B-hf": { DownloadSource.DEFAULT: "kingsley01/InternVL3-1B-hf", DownloadSource.MODELSCOPE: "llamafactory/InternVL3-1B-hf", }, "InternVL3-2B-hf": { DownloadSource.DEFAULT: "kingsley01/InternVL3-2B-hf", DownloadSource.MODELSCOPE: "llamafactory/InternVL3-2B-hf", }, "InternVL3-8B-hf": { DownloadSource.DEFAULT: "kingsley01/InternVL3-8B-hf", DownloadSource.MODELSCOPE: "llamafactory/InternVL3-8B-hf", }, }, template="intern_vl", multimodal=True, )
InternVL 1技术深度分析
1. 引言
InternVL(Internal Vision-Language model)是一个开源的多模态大型模型项目,由上海人工智能实验室(OpenGVLab)开发。InternVL 1是该项目的第一个主要版本,它通过创新的视觉-语言融合方法,实现了强大的图像理解和多模态对话能力。本文将深入分析InternVL 1的技术架构、关键特性和创新点,以提供对该模型的全面了解。
Spatial Layout Projector (SLP)
-
InternVL采用了一种称为"Spatial Layout Projector (SLP)"的方法,将四维的空间坐标[x1,y1,x2,y2](一个bounding box)转换为单个token嵌入:
"A key innovation in LayTextLLM is the Spatial Layout Projector (SLP), which transforms a spatial layout into a singular bounding box token. This enhancement enables the model to process both spatial layouts and textual inputs simultaneously. To be specifically, each OCR-derived spatial layout is represented by a bounding box defined by four-dimensional coordinates [x1,y1,x2,y2]..."
-
这种方法确实将每个边界框(box)表示为一个token,不同于之前的"coordinate-as-tokens"方案(这种方案会将坐标转换为多个token):
"Compared to the coordinate-as-tokens scheme, the SLP represents each bounding box with a single token. This approach significantly reduces the number of input tokens..."
-
这种单token表示法的计算方式是通过将坐标映射到高维空间来实现的:
"The process can be computed as z=W⋅c+b, where c∈ℝ^4 is the vector of the bounding box coordinates. W∈ℝ^(d×4) is a weight matrix with d represents the dimension of the embedding, b∈ℝ^(d×1) is a bias vector, z is the resulting bounding box token represented as an d-dimensional embedding."
这里有一个很好的例子:https://thingsboard.io/use-cases/fleet-tracking/
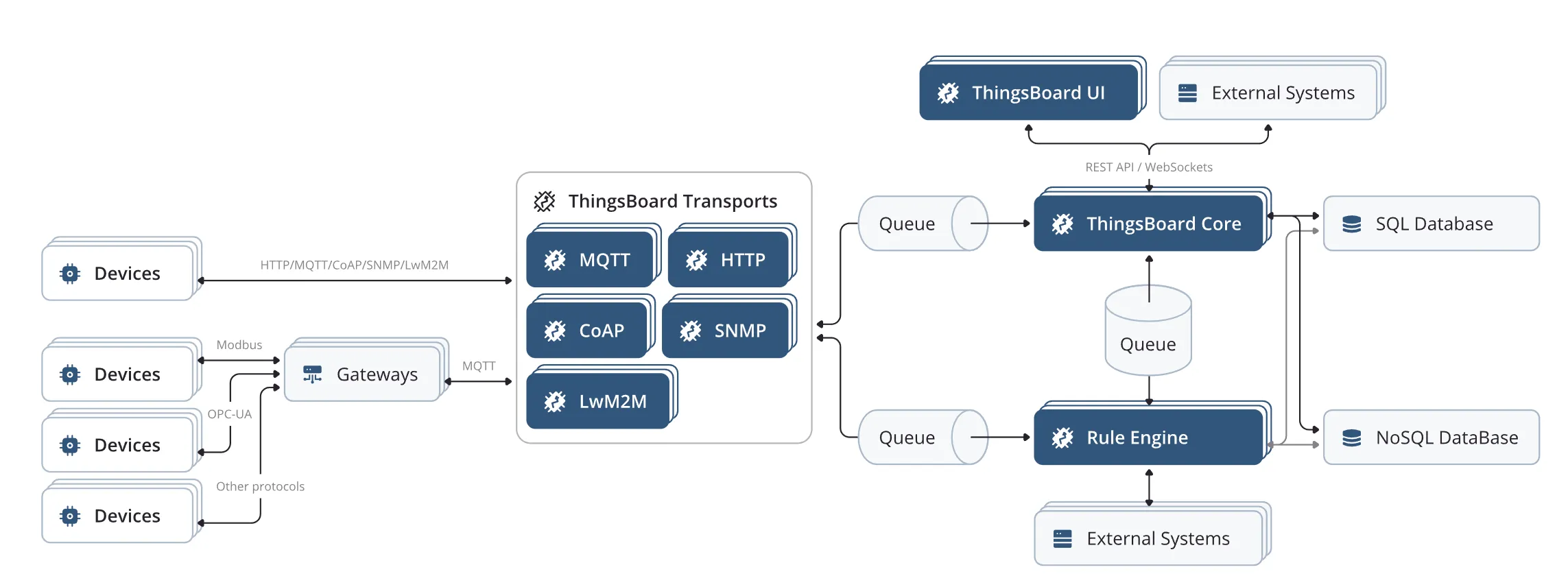
这篇文章想完成这些事情:
- 在 thingsboard 新建GPS设备。
- 在客户端,使用Python模拟为GPS设备,往thingsboard 发送GPS数据(经纬度)。
- 在 thingsboard 仪表盘展示设备的GPS位置轨迹。
- 在 thingsboard 定义虚拟边界使用地理围栏,设置区域。当设备进入或离开地理围栏时触发操作,例如发送短信警告、发出警报或启动工作流。
- 学习如何取得 thingsboard 的设备数据。
- 学习配置 thingsboard 数据转发,将数据存入自己的数据库。
在VMware Ubuntu中访问Windows共享文件夹:完整指南
在使用VMware运行Ubuntu虚拟机时,访问Windows主机上的文件是常见需求。本文将详细介绍如何通过网络共享方式,让Ubuntu虚拟机直接访问Windows主机的文件夹。
解决 PowerShell 中 Conda 命令无法识别的问题
问题描述
在 Windows PowerShell 中运行 conda 时,可能会遇到以下错误:
powershell展开代码conda : 无法将“conda”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。
即使 conda.exe 路径已添加到环境变量,仍然无法直接使用 conda 命令。本指南将提供完整的解决方案。
