时序预测深度学习技术全面汇总
目录
时序预测深度学习技术全面汇总
一、基础循环神经网络模型
1. 循环神经网络(RNN)
- 原理:通过隐藏状态保留前一时刻的信息,处理序列数据的时序依赖性
- 特点:适合捕捉时间序列的动态变化,但存在梯度消失和梯度爆炸问题
- 应用:金融、语音识别、自然语言处理
2. 长短期记忆网络(LSTM)
- 原理:引入门控机制(输入门、遗忘门、输出门),有效解决长期依赖问题
- 优势:能够学习和记住长期依赖关系,缓解梯度消失问题
- 应用:股价预测、电力负荷预测、天气预测
3. 门控循环单元(GRU)
- 原理:LSTM的简化版本,合并输入门和遗忘门为更新门
- 优势:计算效率更高,参数更少,性能与LSTM相近
- 应用:资源受限环境下的时序预测任务
二、卷积神经网络在时序预测中的应用
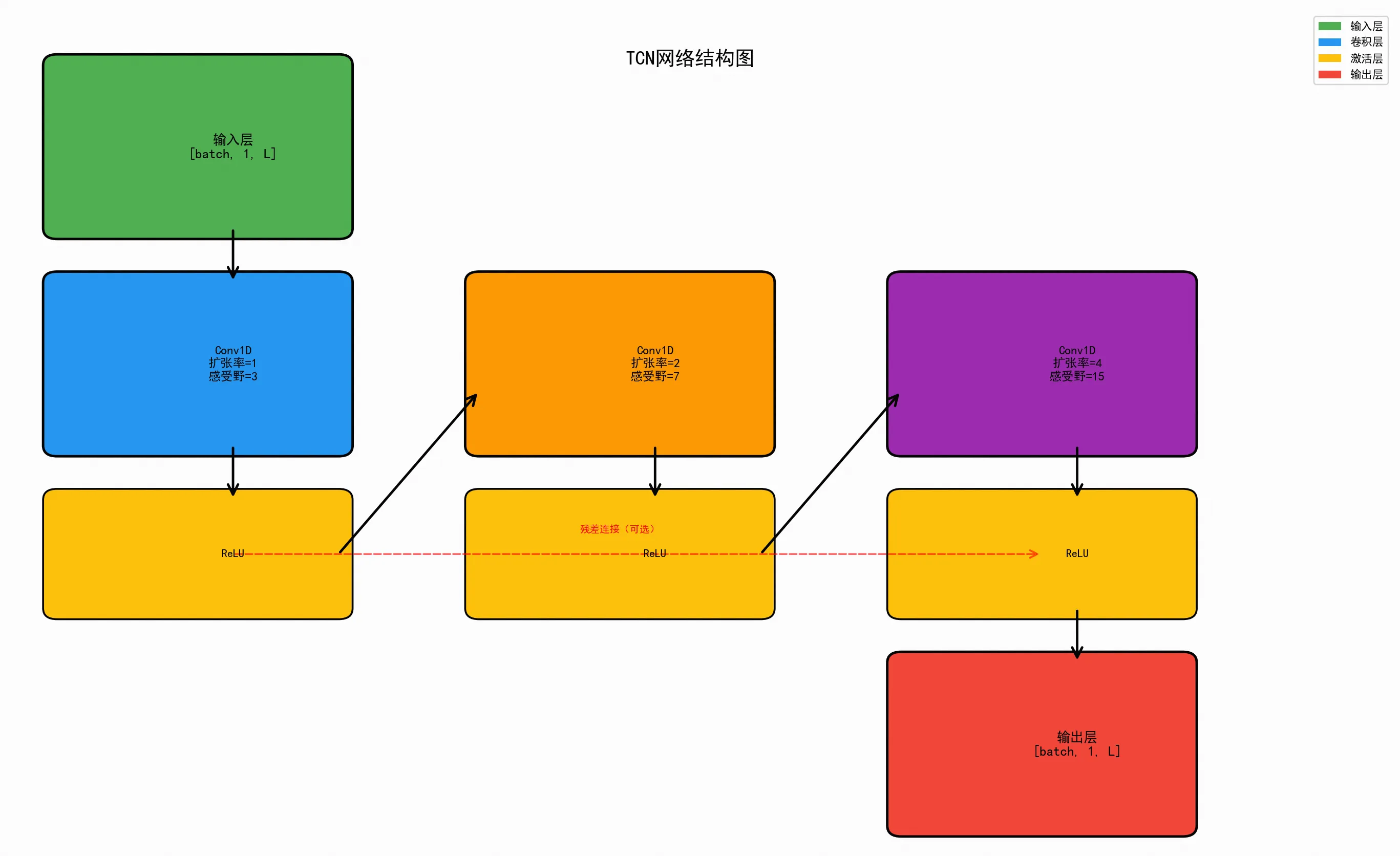
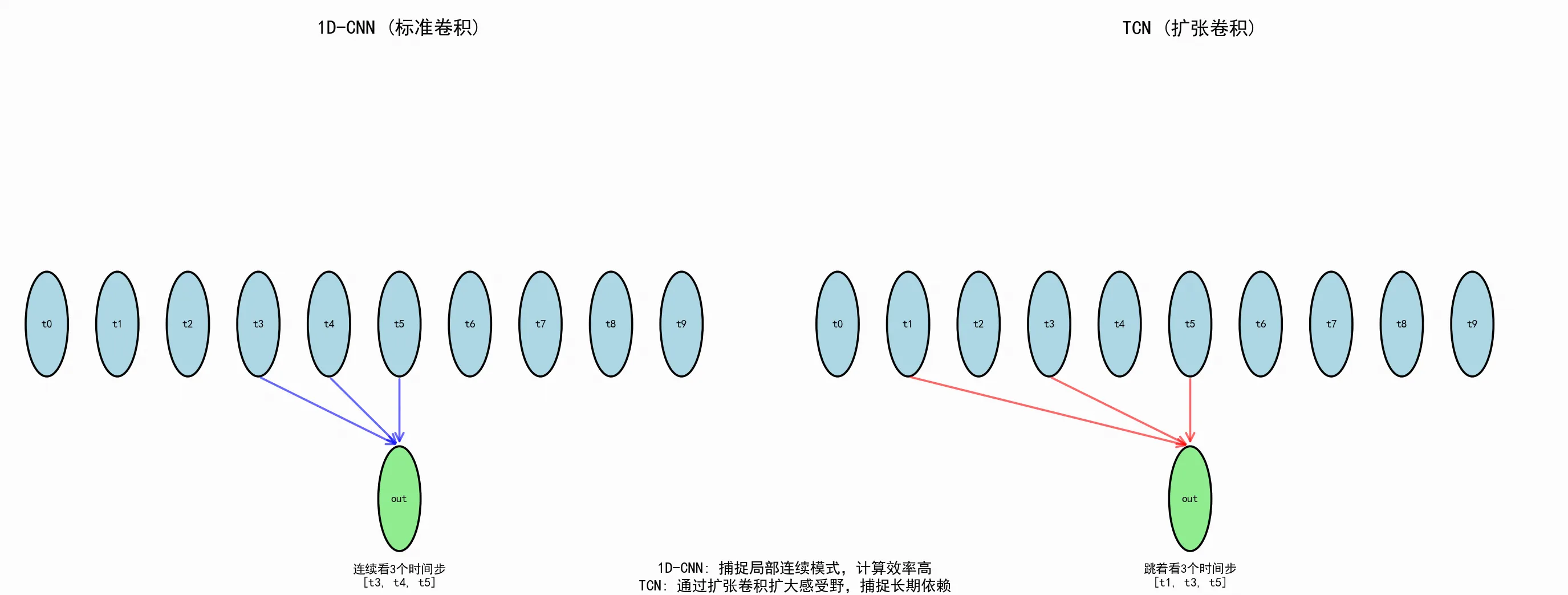
4. 时间卷积网络(TCN, Temporal Convolutional Network)
- 原理:使用因果卷积和扩张卷积,增加感受野以捕捉长距离依赖
- 特点:
- 并行计算优势
- 稳定的梯度传播
- 可变长度输入
- 应用:多变量时间序列预测、概率预测框架
- 因果卷积: 只看当前和过去,不看未来
- 扩张卷积: 通过跳跃采样扩大感受野
- 多层堆叠: 每层扩张率翻倍,感受野指数增长
- 输入输出: 可以灵活设计,输入N步,输出M步
示例代码:
python展开代码"""
TCN (时间卷积网络) 模型定义
"""
import torch
import torch.nn as nn
class SimpleTCN(nn.Module):
"""简单的TCN网络"""
def __init__(self, input_size=1, output_size=1, num_channels=64, kernel_size=3, num_layers=3):
super(SimpleTCN, self).__init__()
layers = []
# 第一层:输入层
layers.append(nn.Conv1d(
input_size, num_channels, kernel_size,
padding=(kernel_size-1) * (2**0), # 扩张率=1的padding
dilation=1
))
layers.append(nn.ReLU())
# 中间层:扩张率逐渐增大 (1, 2, 4, 8, ...)
for i in range(1, num_layers):
dilation = 2 ** i
padding = (kernel_size - 1) * dilation
layers.append(nn.Conv1d(
num_channels, num_channels, kernel_size,
padding=padding,
dilation=dilation
))
layers.append(nn.ReLU())
# 输出层
layers.append(nn.Conv1d(num_channels, output_size, 1))
self.network = nn.Sequential(*layers)
def forward(self, x):
"""
Args:
x: [batch, channels, length]
例如: [1, 1, 100] 表示批次1,通道1,长度100
Returns:
[batch, output_size, length]
"""
return self.network(x)
class TCNPredictor(nn.Module):
"""用于预测的TCN"""
def __init__(self, input_size=1, input_len=10, output_len=5, num_channels=32, kernel_size=3, num_layers=3):
super(TCNPredictor, self).__init__()
self.input_len = input_len
self.output_len = output_len
# TCN编码器:处理输入序列
self.encoder = SimpleTCN(
input_size=input_size,
output_size=num_channels,
num_channels=num_channels,
kernel_size=kernel_size,
num_layers=num_layers
)
# 预测头:生成未来序列
self.predictor = nn.Conv1d(num_channels, 1, 1)
def forward(self, x):
"""
Args:
x: [batch, input_size, input_len] - 过去的序列
Returns:
[batch, 1, output_len] - 未来的预测
"""
# 编码
encoded = self.encoder(x) # [batch, num_channels, input_len]
# 取最后几个时间步作为特征
features = encoded[:, :, -self.output_len:] # [batch, num_channels, output_len]
# 预测
prediction = self.predictor(features) # [batch, 1, output_len]
return prediction
5. 一维卷积神经网络(1D-CNN)
- 原理:通过一维卷积操作提取时间序列的局部模式和特征
- 优势:捕捉短期时间依赖性,计算效率高
- 应用:传感器数据分析、短期预测任务
三、Transformer架构及其变体
6. Transformer基础模型
- 核心机制:自注意力机制(Self-Attention)
- 优势:
- 能够捕捉全局依赖关系
- 并行处理序列数据
- 适合长序列建模
- 应用:长序列时间序列预测、多变量预测
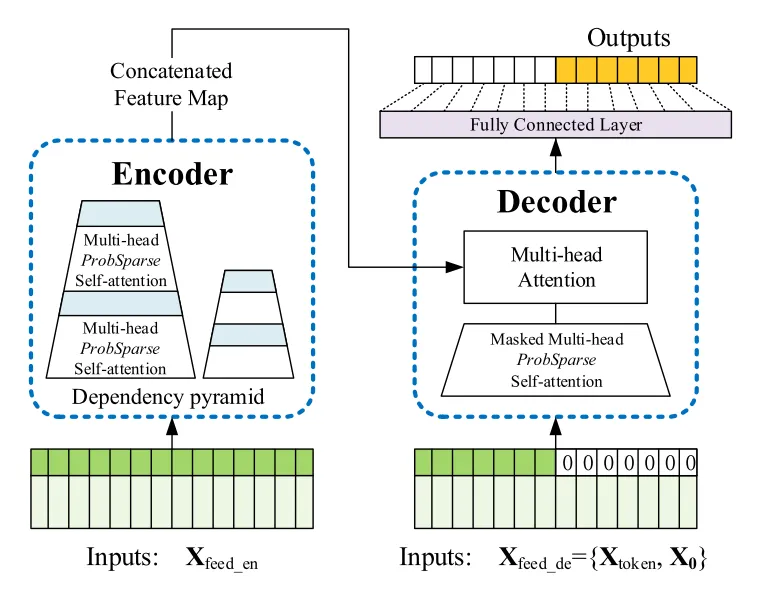
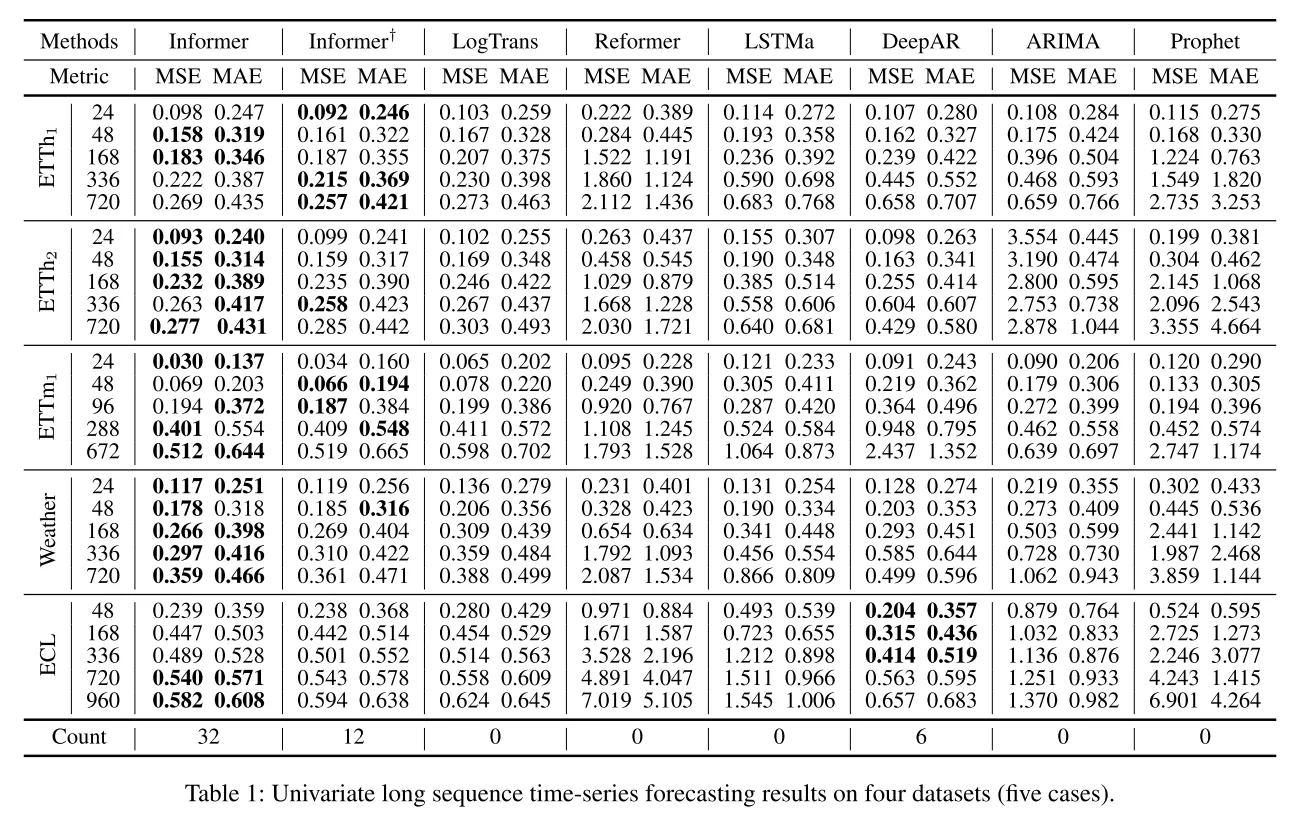
7. Informer模型
- 特点:高效的自注意力机制,降低计算复杂度
- 改进:ProbSparse自注意力机制
- 应用:长时间序列预测任务
https://github.com/zhouhaoyi/Informer2020
主要创新点:
- ProbSparse Self-Attention:稀疏注意力机制,降低计算复杂度
- Self-attention Distilling:自注意力蒸馏,压缩编码器输出
- Generative Style Decoder:生成式解码器,一次性预测长序列
组件结构:
展开代码Informer ├── enc_embedding (DataEmbedding) ├── dec_embedding (DataEmbedding) ├── encoder (Encoder) │ ├── EncoderLayer × e_layers │ │ ├── AttentionLayer (ProbAttention/FullAttention) │ │ └── Conv1D FFN │ └── ConvLayer (蒸馏层) × (e_layers-1) ├── decoder (Decoder) │ └── DecoderLayer × d_layers │ ├── Self-Attention (ProbAttention) │ ├── Cross-Attention (FullAttention) │ └── Conv1D FFN └── projection (Linear层)
展开代码## Informer vs Transformer 主要区别 ### 1. **注意力机制** - **Transformer**: Full Attention,计算所有查询的注意力,复杂度 O(L²) - **Informer**: ProbSparse Attention,只计算 top-u 个“活跃”查询,复杂度降至 O(L log L) ### 2. **编码器蒸馏** - **Transformer**: 编码器层之间没有压缩 - **Informer**: 在编码器层之间插入 ConvLayer,用卷积+池化压缩序列长度,减少计算 ### 3. **前馈网络** - **Transformer**: 标准的两层 Linear 全连接层(Linear → ReLU → Linear) - **Informer**: 用 Conv1D 卷积替代,更适合序列数据 ### 4. **嵌入层** - **Transformer**: Token Embedding + Positional Embedding - **Informer**: 额外加入时间特征嵌入(小时、日期、月份等),更适合时间序列 ### 5. **解码方式** - **Transformer**: 自回归,逐步生成下一个 token - **Informer**: 生成式,一次性预测整个未来序列 ### 6. **应用场景** - **Transformer**: 主要用于 NLP(翻译、生成等) - **Informer**: 专门用于长序列时间序列预测 **核心优势**:Informer 通过稀疏注意力和序列压缩,在处理长序列时更高效,同时保持了预测精度。
https://github.com/logtransfergit/LogTransfer
https://github.com/lucidrains/reformer-pytorch
8. Autoformer模型
- 特点:采用自相关机制(Auto-Correlation)替代自注意力
- 优势:更好地捕捉时间序列的周期性和趋势
- 应用:具有强周期性的时序数据预测
https://github.com/thuml/Autoformer
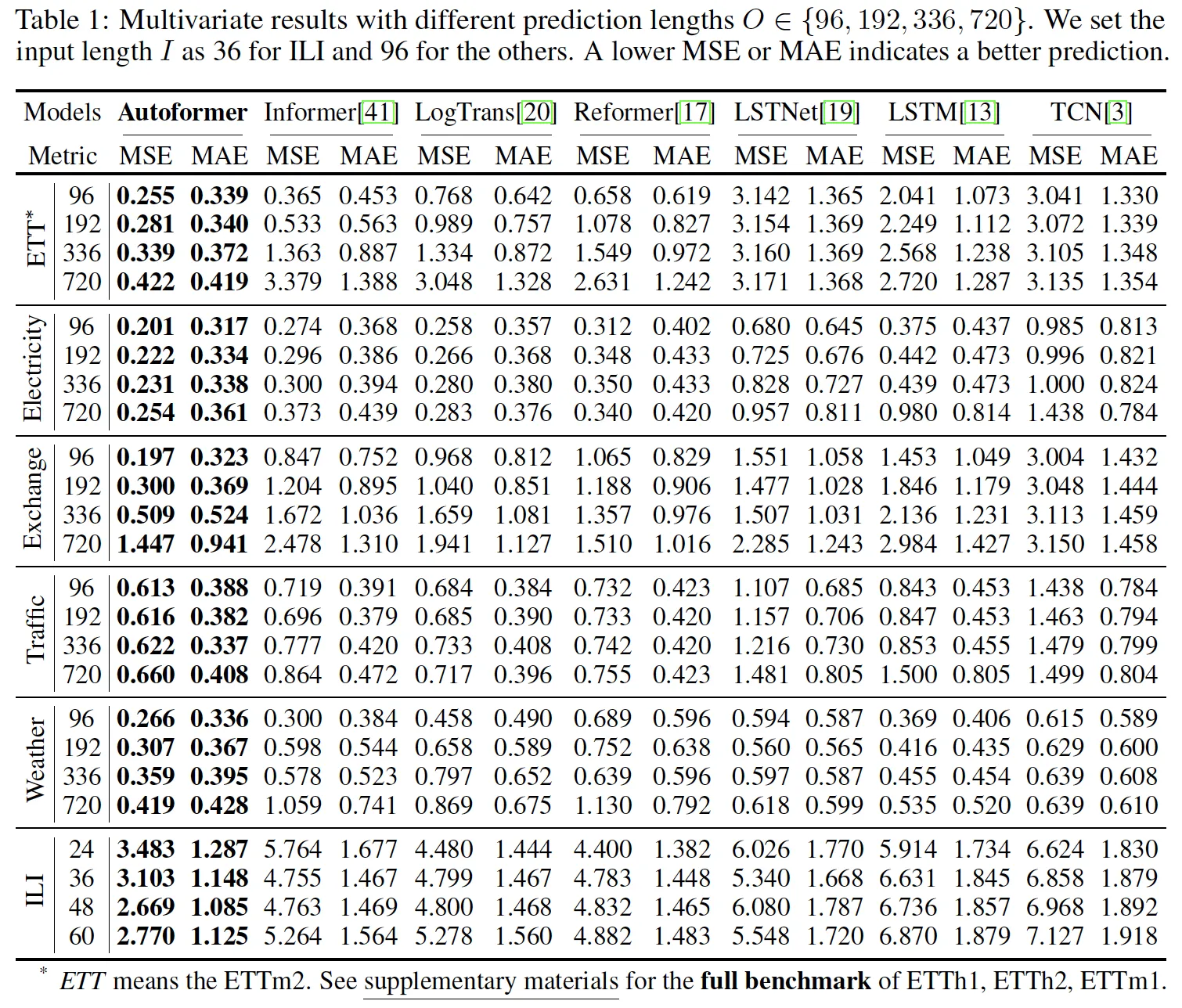
9. FEDformer模型
- 特点:结合傅里叶变换和小波变换进行特征提取
- 优势:在频域和时域同时建模,提升预测精度
- 应用:复杂的多周期时间序列
https://github.com/MAZiqing/FEDformer
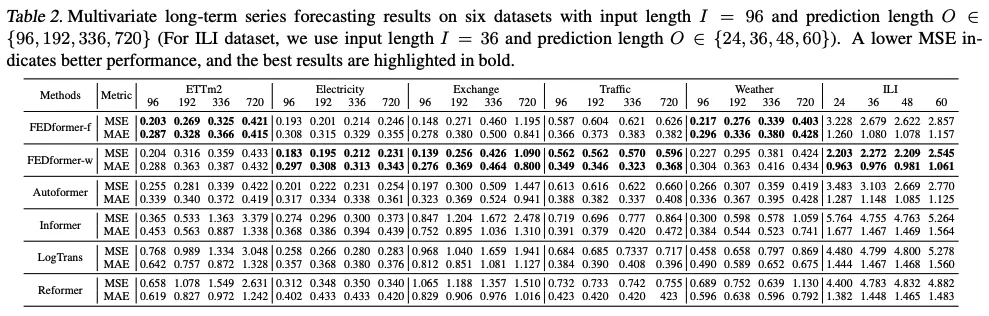
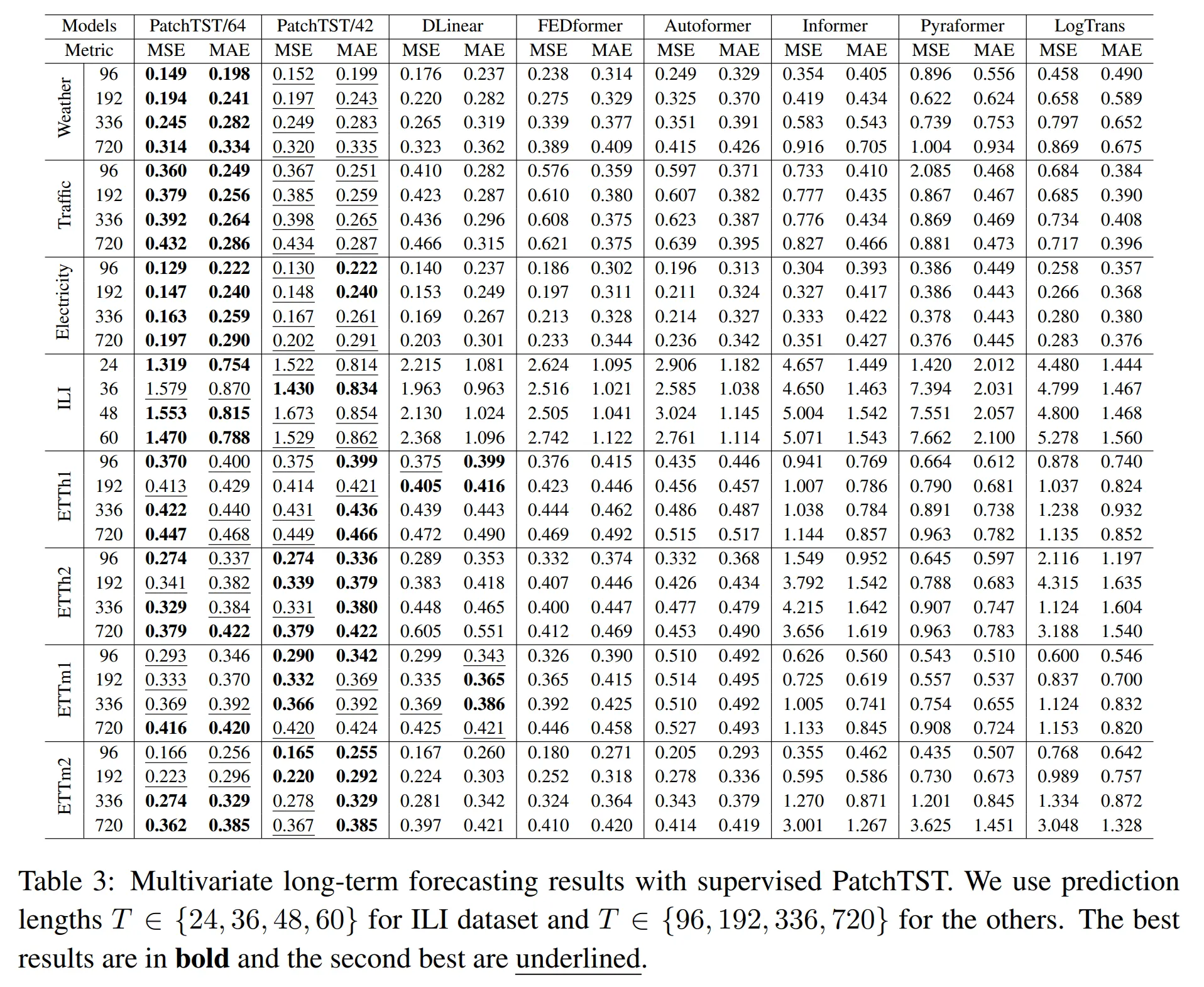
10. PatchTST
- 原理:将时间序列划分为补丁(Patch),使用Transformer处理
- 优势:降低计算复杂度,提升局部特征提取能力
- 应用:大规模时间序列预测
https://github.com/yuqinie98/PatchTST
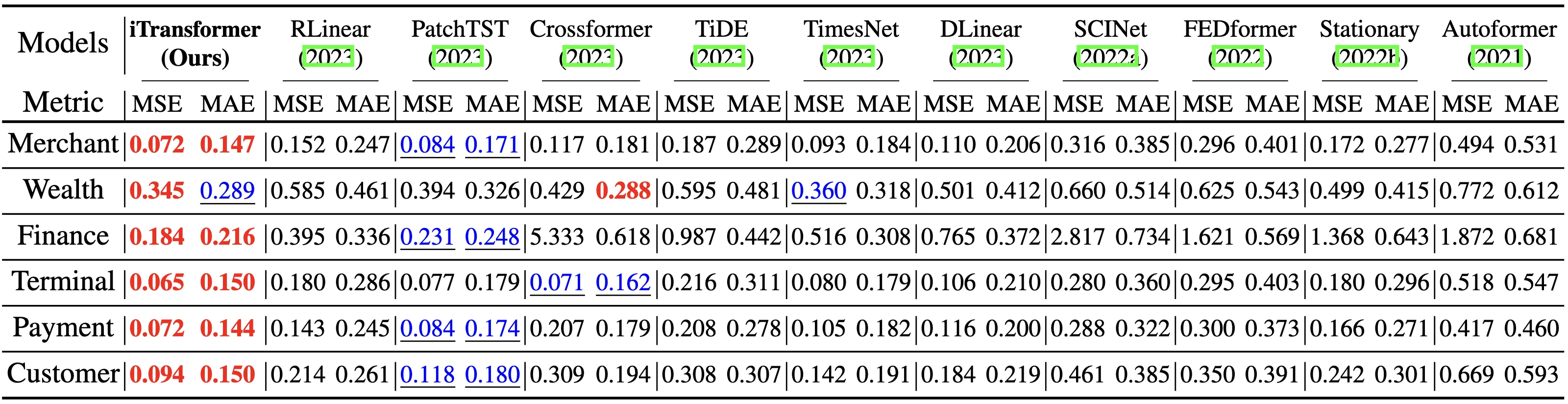
11. iTransformer
- 特点:将变量维度作为序列维度,时间维度作为特征维度
- 创新:反转传统Transformer的维度处理方式
- 应用:多变量时间序列预测
https://github.com/thuml/iTransformer
12. TimesNet模型
- 原理:将一维时间序列转换为二维张量,利用二维卷积捕捉多周期性
- 特点:
- 多周期性建模
- 2D卷积提取复杂时间变化模式
- 应用:预测、分类、异常检测等多种时序分析任务
https://github.com/thuml/TimesNet
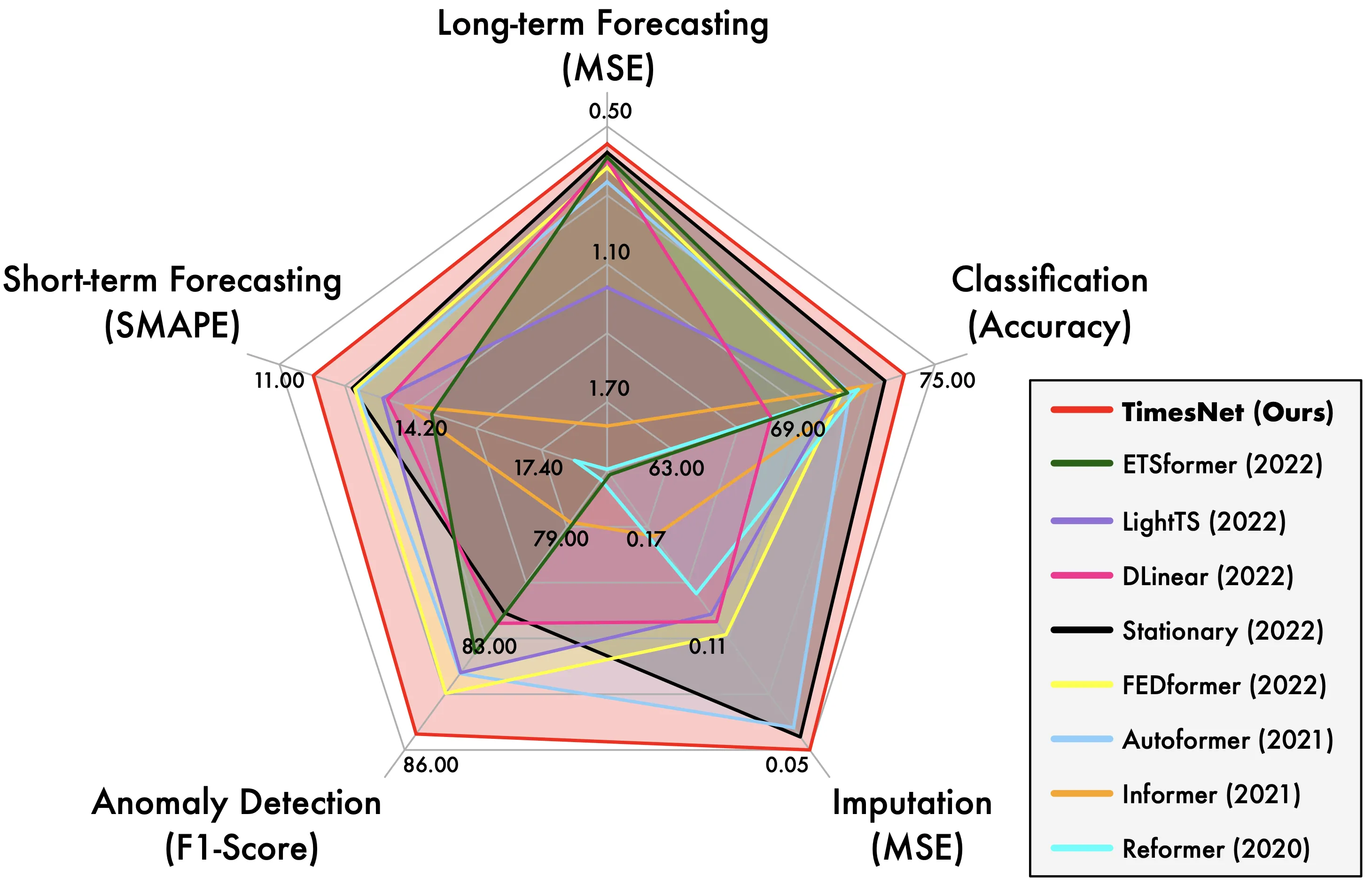
四、专用时序预测模型
13. N-BEATS模型
- 特点:无先验知识的深度学习架构,专为时序预测设计
- 原理:通过堆叠全连接层,自动学习趋势和季节性成分
- 优势:可解释性强,预测性能优异
14. N-HiTS模型
- 特点:N-BEATS的改进版本
- 改进:多尺度架构,更高效的多层次分解
- 应用:长期预测任务
15. DeepAR模型
- 原理:基于自回归循环网络的概率预测方法
- 特点:
- 生成概率预测而非点预测
- 在大量相关时间序列上训练
- 应用:大规模相关时间序列的预测(如零售需求预测)
16. Temporal Fusion Transformer (TFT)
- 特点:结合静态协变量、已知未来输入和观察到的输入
- 优势:处理多种输入类型,可解释性强
- 应用:多变量预测,需要协变量的场景
五、状态空间模型
17. Mamba架构
- 原理:基于选择性状态空间模型(S4, Structured State Space Sequence Model)
- 特点:
- 动态参数选择机制
- 硬件感知算法优化
- 线性时间复杂度
- 优势:高效处理超长序列,计算效率高
- 应用:长序列时间序列预测,多模态深度学习
18. 结构化状态空间序列模型(S4)
- 原理:结合连续时间、循环和卷积模型
- 特点:能够处理不规则采样的数据和长上下文
- 应用:复杂序列建模任务
六、物理信息与混合方法
19. 物理信息神经网络(PINN)
- 原理:将物理定律嵌入神经网络,作为正则化项
- 特点:
- 数据稀缺时表现优异
- 提高模型的泛化能力
- 确保预测符合物理规律
- 应用:偏微分方程求解、物理系统时序预测
20. 时序分解与机器学习结合
- 方法:将时间序列分解为趋势、季节性和残差分量
- 模型:使用随机森林、梯度提升等方法对各分量建模
- 优势:提高多步预测的准确性
- 应用:具有明显趋势和季节性的数据
七、表示学习与预训练
21. TS2Vec模型
- 原理:通用时间序列表示学习框架
- 特点:
- 分层对比学习
- 时间戳级别的表示
- 应用:分类、预测、异常检测等多种任务
22. 时序预测预训练模型
- 方法:掩码建模(Masked Modeling)
- 特点:在大规模数据上预训练,迁移到下游任务
- 趋势:类似BERT的时序预测预训练模型(如TimeGPT)
23. TimeGPT
- 特点:大规模时序预测基础模型
- 原理:基于GPT架构的时间序列预训练模型
- 应用:零样本时序预测,快速适应新任务
八、图神经网络与时序
24. 图神经网络(GNN)在时序预测中的应用
- 原理:建模变量间的空间依赖关系
- 特点:
- 捕捉多变量时间序列中的动态依赖
- 结合时间维度和空间维度
- 应用:交通流预测、传感器网络数据
25. ReGENN(Recurrent Graph Evolution Neural Network)
- 特点:结合图演化和深度循环学习
- 原理:建模多变量时间序列中的动态依赖关系
- 应用:复杂系统的时空预测
九、时空预测模型
26. PredRNN模型
- 原理:用于时空预测学习的循环神经网络
- 特点:
- 双向记忆流
- 记忆解耦损失
- 生成未来图像
- 应用:视频预测、时空序列预测
27. DESIRE框架
- 原理:深度随机逆最优控制RNN编码器-解码器框架
- 特点:预测动态场景中多个交互代理的未来位置
- 应用:多智能体交互预测、自动驾驶场景预测
十、概率与不确定性预测
28. 概率预测方法
- 技术:
- 分位数回归(Quantile Regression)
- 高斯过程(Gaussian Process)
- 变分推理(Variational Inference)
- 优势:提供预测的不确定性估计
- 应用:风险管理、决策支持系统
29. 不确定性量化(Uncertainty Quantification)
- 方法:
- 蒙特卡洛Dropout
- 集成方法
- 置信区间估计
- 应用:需要可靠性的预测任务
十一、自监督与对比学习
30. 对比学习在时序预测中的应用
- 原理:通过对比正负样本学习时间序列表示
- 方法:
- 时间增强
- 多视图学习
- 优势:减少对标签数据的依赖
31. 自监督学习
- 方法:
- 掩码重建
- 时间对比
- 预测性编码
- 应用:数据稀缺场景下的预训练
十二、强化学习与时序预测
32. 深度强化学习(DRL)在时序预测中的应用
- 原理:通过与环境交互学习最优策略
- 应用场景:
- 投资组合优化
- 资源调度
- 动态定价
- 优势:能够处理决策相关的时序预测任务
十三、频域与时域分析
33. 傅里叶变换方法
- 应用:频域特征提取
- 模型:FEDformer等结合频域分析的模型
- 优势:捕捉周期性模式
34. 小波变换方法
- 应用:多尺度时间序列分析
- 特点:同时提供时域和频域信息
- 模型:FEDformer等
35. 时序分解方法
- 方法:
- STL分解(Seasonal and Trend decomposition using Loess)
- EMD(Empirical Mode Decomposition)
- X-13ARIMA-SEATS
- 应用:趋势和季节性提取
十四、多模态时序预测
36. 多模态学习
- 原理:整合文本、图像、音频等多种数据源
- 趋势:2025年潜在热点方向
- 应用:
- 结合传感器数据和图像数据
- 文本情感分析与数值预测结合
十五、大语言模型与时序预测
37. 大语言模型(LLM)集成
- 趋势:利用GPT等大模型的时序理解能力
- 方法:
- 提示工程(Prompt Engineering)
- 微调(Fine-tuning)
- 应用:需要外部知识注入的预测任务
十六、评估指标与基准
38. 评估指标
- 点预测指标:
- MAE(平均绝对误差)
- RMSE(均方根误差)
- MAPE(平均绝对百分比误差)
- 概率预测指标:
- CRPS(连续排名概率分数)
- 分位数损失
39. 基准数据集
- 经典数据集:
- UCR时间序列分类档案
- Monash时间序列预测仓库
- 应用领域数据集:
- 电力负荷数据
- 交通流量数据
- 金融时间序列
十七、工程实现与工具
40. 深度学习框架
- PyTorch:灵活的深度学习框架,广泛用于研究
- TensorFlow/Keras:生产环境常用框架
- JAX:高性能科学计算框架
41. 时序预测专用库
- Darts:统一的时间序列预测库,支持多种模型
- GluonTS:亚马逊开发的概率时间序列建模工具包
- TSAI(Time Series AI):基于fastai的时序预测库
- NeuralForecast:神经时序预测模型集合
- Prophet:Facebook开发的时序预测工具
42. 时间序列数据库
- InfluxDB:专为时序数据设计的数据库
- TimescaleDB:基于PostgreSQL的时序数据库扩展
- Prometheus:监控和时序数据库
十八、应用场景
43. 金融领域
- 股价预测
- 汇率预测
- 交易量预测
- 风险管理
44. 电力系统
- 电力负荷预测
- 可再生能源发电预测
- 需求响应优化
45. 交通领域
- 交通流量预测
- 出行需求预测
- 拥堵预测
46. 气象预报
- 温度、降水预测
- 极端天气预警
- 气候模式分析
47. 工业制造
- 设备故障预测
- 质量预测
- 供应链需求预测
48. 零售与电商
- 销量预测
- 库存优化
- 需求预测
十九、前沿研究方向
49. 可解释性时序预测
- 方法:
- SHAP值分析
- 注意力权重可视化
- 特征重要性分析
- 重要性:增强模型的可信度和可接受性
50. 在线学习与时序预测
- 挑战:数据流不断更新
- 方法:
- 增量学习
- 模型适配
- 应用:实时系统、边缘计算
51. 少样本学习(Few-shot Learning)
- 方法:
- 元学习(Meta-learning)
- 迁移学习
- 应用:新领域快速适应,数据稀缺场景
52. 联邦学习在时序预测中的应用
- 特点:保护隐私的分布式学习
- 挑战:时序数据的非独立同分布特性
- 应用:跨组织合作、隐私敏感场景
53. 边缘计算与时序预测
- 需求:低延迟、低功耗
- 技术:
- 模型压缩
- 知识蒸馏
- 应用:IoT设备、实时监控
二十、技术挑战与解决方案
54. 非平稳数据处理
- 挑战:时间序列统计特性随时间变化
- 解决方案:
- 自适应归一化
- 差分处理
- 分段建模
55. 缺失值处理
- 方法:
- 插值方法(线性、样条、卡尔曼滤波)
- 生成模型填充
- 注意力机制处理缺失
56. 异常值处理
- 方法:
- 异常检测
- 鲁棒损失函数
- 自适应阈值
57. 多步预测策略
- 方法:
- 递归策略(Recursive)
- 直接策略(Direct)
- 多输出策略(Multi-output)
58. 长期预测挑战
- 问题:预测误差累积
- 解决方案:
- 分解策略
- 多尺度建模
- 注意力机制
59. 因果推断与时序预测
- 挑战:区分相关性和因果关系
- 方法:
- 因果图模型
- 工具变量
- 差分差分法
二十一、未来发展趋势
60. 大规模预训练模型
- 趋势:类似TimeGPT的基础模型
- 优势:零样本学习能力,快速适应
61. 多模态融合
- 趋势:结合图像、文本、数值数据
- 应用:更丰富的上下文信息
62. 可解释AI
- 趋势:提高模型透明度
- 方法:注意力可视化、SHAP分析
63. 绿色AI
- 趋势:降低计算成本
- 方法:模型压缩、高效架构
64. 自动化机器学习(AutoML)
- 趋势:自动特征工程、超参数优化
- 应用:降低使用门槛
总结
时序预测是深度学习领域的重要课题,技术不断演进:
经典方法:RNN、LSTM、GRU仍然广泛使用 现代架构:Transformer及其变体在长序列预测中表现出色 前沿趋势:预训练模型、多模态学习、可解释性增强
选择合适的模型需要根据:
- 数据特性(单变量/多变量、长度、周期性)
- 应用场景(金融、电力、交通等)
- 计算资源(实时性要求、硬件限制)
- 预测需求(点预测/概率预测、短期/长期)
随着技术的不断发展,时序预测在准确性、效率和应用范围方面将持续提升。
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录